우리가 만든 모델이 얼마나 좋은 모델인지 평가하는 방법
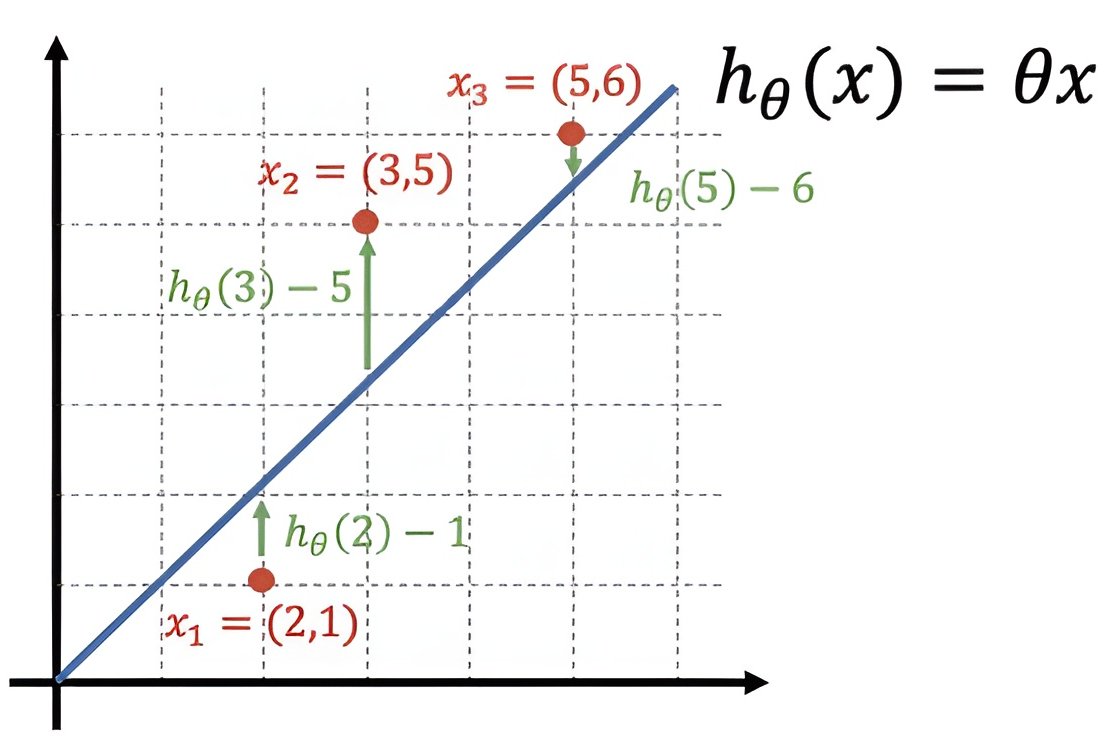
분류모델의 평가
분류모델은 예측값과 실제값이 일치하는지 여부를 기준으로 평가한다.
이진분류 모델 평가
이진분류는 두 개의 클래스를 구분하는 문제다.
Confusion Matrix (혼동 행렬)
Confusion Matrix는 모델의 예측 결과를 실제값과 비교하여 표로 나타낸 것이다.
| 예측: Positive | 예측: Negative | |
|---|---|---|
| 실제: Positive | TP (True Positive) | FN (False Negative) |
| 실제: Negative | FP (False Positive) | TN (True Negative) |
- TP (True Positive): 실제 Positive를 Positive로 올바르게 예측
- TN (True Negative): 실제 Negative를 Negative로 올바르게 예측
- FP (False Positive): 실제 Negative를 Positive로 잘못 예측 (1종 오류)
- FN (False Negative): 실제 Positive를 Negative로 잘못 예측 (2종 오류)
Accuracy (정확도)
전체 예측 중 올바르게 예측한 비율이다.
- 의미: 전체적으로 얼마나 맞췄는지
- 장점: 직관적이고 이해하기 쉬움
- 단점: 클래스 불균형 데이터에서는 부정확할 수 있음
Precision (정밀도)
Positive로 예측한 것 중 실제로 Positive인 비율이다.
- 의미: Positive로 예측한 것의 신뢰도
- 사용 시나리오: False Positive를 최소화해야 할 때
Recall (재현율, Sensitivity)
실제 Positive 중 Positive로 올바르게 예측한 비율이다.
- 의미: 실제 Positive를 얼마나 잘 찾아내는지
- 사용 시나리오: False Negative를 최소화해야 할 때
F1 Score
Precision과 Recall의 조화 평균이다.
- 의미: Precision과 Recall의 균형
- 사용 시나리오: 두 지표를 모두 고려해야 할 때
ROC AUC
ROC 곡선 아래 면적을 나타내는 지표다.
- ROC 곡선: Receiver Operating Characteristic 의 약자. 다양한 threshold에서 TPR(True Positive Rate)과 FPR(False Positive Rate)의 관계를 나타낸 곡선
- TPR (Sensitivity): = Recall
- FPR:
- AUC: Area Under the Curve 의 약자. 0~1 사이의 값, 1에 가까울수록 좋음
- 의미: 모델이 Positive와 Negative를 얼마나 잘 구분하는지
Threshold (임계값)
분류 모델은 확률을 출력하고, 이 확률을 기준으로 클래스를 결정한다. 이 기준이 되는 값이 threshold다.
- 기본 threshold: 0.5 (확률이 0.5 이상이면 Positive)
- Threshold 조정: Precision과 Recall 사이의 트레이드오프
- Threshold ↑ → Precision ↑, Recall ↓
- Threshold ↓ → Precision ↓, Recall ↑
- 최적 threshold 선택:
- F1 Score가 최대가 되는 지점
- Precision-Recall 곡선에서 균형점
- 비즈니스 요구사항에 따라 선택
유방암 양성/음성 이진분류 모델 평가하기
유방암 데이터셋을 사용하여 이진분류 모델의 평가 지표를 계산하고 시각화한다.
In [19]:
# 필요한 라이브러리 import
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import (
confusion_matrix, accuracy_score, precision_score,
recall_score, f1_score, roc_auc_score, roc_curve,
precision_recall_curve, classification_report
)
from sklearn.preprocessing import StandardScaler
# 데이터 로드
data = load_breast_cancer()
X = pd.DataFrame(data.data, columns=data.feature_names)
y = data.target # 0: 악성, 1: 양성
print(f"데이터 크기: {X.shape}")
print(f"클래스 분포:\n{pd.Series(y).value_counts()}")
데이터 크기: (569, 30) 클래스 분포: 1 357 0 212 Name: count, dtype: int64
In [20]:
# 데이터 분리
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42, stratify=y
)
# 데이터 스케일링
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
# 모델 학습
model = LogisticRegression(max_iter=1000, random_state=42)
model.fit(X_train_scaled, y_train)
# 예측
y_pred = model.predict(X_test_scaled)
y_pred_proba = model.predict_proba(X_test_scaled)[:, 1] # 양성 클래스 확률
print("모델 학습 완료")
모델 학습 완료
In [21]:
# Confusion Matrix 계산
cm = confusion_matrix(y_test, y_pred)
print("Confusion Matrix:")
print(cm)
print()
# TP, TN, FP, FN 추출
TN, FP, FN, TP = cm.ravel()
print(f"TP (True Positive): {TP}")
print(f"TN (True Negative): {TN}")
print(f"FP (False Positive): {FP}")
print(f"FN (False Negative): {FN}")
print()
# Confusion Matrix 시각화
plt.figure(figsize=(8, 6))
sns.heatmap(cm, annot=True, fmt='d', cmap='Blues',
xticklabels=['Malignant', 'Benign'],
yticklabels=['Malignant', 'Benign'])
plt.ylabel('Actual')
plt.xlabel('Predicted')
plt.title('Confusion Matrix')
plt.show()
Confusion Matrix: [[41 1] [ 1 71]] TP (True Positive): 71 TN (True Negative): 41 FP (False Positive): 1 FN (False Negative): 1

In [22]:
# 평가 지표 계산
accuracy = accuracy_score(y_test, y_pred)
precision = precision_score(y_test, y_pred)
recall = recall_score(y_test, y_pred)
f1 = f1_score(y_test, y_pred)
roc_auc = roc_auc_score(y_test, y_pred_proba)
print("=== 평가 지표 ===")
print(f"Accuracy: {accuracy:.4f}")
print(f"Precision: {precision:.4f}")
print(f"Recall: {recall:.4f}")
print(f"F1 Score: {f1:.4f}")
print(f"ROC AUC: {roc_auc:.4f}")
print()
# 공식으로 직접 계산하여 검증
print("=== 공식으로 직접 계산 ===")
print(f"Accuracy: {(TP + TN) / (TP + TN + FP + FN):.4f}")
print(f"Precision: {TP / (TP + FP):.4f}")
print(f"Recall: {TP / (TP + FN):.4f}")
print(f"F1 Score: {2 * (precision * recall) / (precision + recall):.4f}")
=== 평가 지표 === Accuracy: 0.9825 Precision: 0.9861 Recall: 0.9861 F1 Score: 0.9861 ROC AUC: 0.9954 === 공식으로 직접 계산 === Accuracy: 0.9825 Precision: 0.9861 Recall: 0.9861 F1 Score: 0.9861
In [23]:
# ROC 곡선 계산
fpr, tpr, thresholds_roc = roc_curve(y_test, y_pred_proba)
# ROC 곡선 시각화
plt.figure(figsize=(8, 6))
plt.plot(fpr, tpr, label=f'ROC Curve (AUC = {roc_auc:.4f})')
plt.plot([0, 1], [0, 1], 'k--', label='Random Classifier')
plt.xlabel('False Positive Rate (FPR)')
plt.ylabel('True Positive Rate (TPR / Recall)')
plt.title('ROC Curve')
plt.legend()
plt.grid(True)
plt.show()

In [24]:
# 다양한 threshold에서 성능 계산
thresholds = np.arange(0.1, 1.0, 0.05)
precisions = []
recalls = []
f1_scores = []
for threshold in thresholds:
y_pred_thresh = (y_pred_proba >= threshold).astype(int)
precisions.append(precision_score(y_test, y_pred_thresh, zero_division=0))
recalls.append(recall_score(y_test, y_pred_thresh))
f1_scores.append(f1_score(y_test, y_pred_thresh))
# 시각화
plt.figure(figsize=(10, 6))
plt.plot(thresholds, precisions, label='Precision', marker='o')
plt.plot(thresholds, recalls, label='Recall', marker='s')
plt.plot(thresholds, f1_scores, label='F1 Score', marker='^')
plt.xlabel('Threshold')
plt.ylabel('Score')
plt.title('Performance Change by Threshold')
plt.legend()
plt.grid(True)
plt.axvline(x=0.5, color='r', linestyle='--', label='Default Threshold (0.5)')
plt.legend()
plt.show()
# 최적 threshold 찾기 (F1 Score 최대)
optimal_idx = np.argmax(f1_scores)
optimal_threshold = thresholds[optimal_idx]
print(f"최적 Threshold: {optimal_threshold:.2f}")
print(f"최적 F1 Score: {f1_scores[optimal_idx]:.4f}")

최적 Threshold: 0.20 최적 F1 Score: 0.9863
In [25]:
# Precision-Recall 곡선 계산
precision_curve, recall_curve, thresholds_pr = precision_recall_curve(y_test, y_pred_proba)
# Precision-Recall 곡선 시각화
plt.figure(figsize=(8, 6))
plt.plot(recall_curve, precision_curve)
plt.xlabel('Recall')
plt.ylabel('Precision')
plt.title('Precision-Recall Curve')
plt.grid(True)
plt.show()
# Classification Report
print("=== Classification Report ===")
print(classification_report(y_test, y_pred, target_names=['Malignant', 'Benign']))

=== Classification Report ===
precision recall f1-score support
Malignant 0.98 0.98 0.98 42
Benign 0.99 0.99 0.99 72
accuracy 0.98 114
macro avg 0.98 0.98 0.98 114
weighted avg 0.98 0.98 0.98 114
다중분류 모델 평가
다중분류는 세 개 이상의 클래스를 구분하는 문제다. 이진분류와 달리 여러 클래스에 대한 평가가 필요하다.
다중분류 평가 방법
다중분류에서는 각 클래스별로 TP, TN, FP, FN을 계산하고, 이를 종합하는 방법이 세 가지 있다.
1. Macro 평균
각 클래스별 지표를 계산한 후 산술 평균을 구한다.
- 장점: 모든 클래스를 동등하게 취급
- 단점: 클래스 불균형에 민감
2. Micro 평균
모든 클래스의 TP, FP, FN을 합산한 후 지표를 계산한다.
- 장점: 클래스 불균형에 덜 민감
- 단점: 큰 클래스의 영향이 큼
3. Weighted 평균
각 클래스별 지표를 샘플 수로 가중 평균한다.
- 장점: 클래스 불균형을 고려하면서도 각 클래스의 성능을 반영
- 단점: 큰 클래스의 영향이 큼
다중분류 Confusion Matrix
다중분류의 Confusion Matrix는 n×n 행렬이다. 각 행은 실제 클래스, 각 열은 예측 클래스를 나타낸다.
In [26]:
# Wine 데이터셋 로드 (다중분류)
from sklearn.datasets import load_wine
wine_data = load_wine()
X_wine = pd.DataFrame(wine_data.data, columns=wine_data.feature_names)
y_wine = wine_data.target # 3개 클래스
print(f"데이터 크기: {X_wine.shape}")
print(f"클래스 분포:\n{pd.Series(y_wine).value_counts().sort_index()}")
print(f"클래스 이름: {wine_data.target_names}")
데이터 크기: (178, 13) 클래스 분포: 0 59 1 71 2 48 Name: count, dtype: int64 클래스 이름: ['class_0' 'class_1' 'class_2']
In [27]:
# 데이터 분리
X_train_wine, X_test_wine, y_train_wine, y_test_wine = train_test_split(
X_wine, y_wine, test_size=0.2, random_state=42, stratify=y_wine
)
# 데이터 스케일링
scaler_wine = StandardScaler()
X_train_wine_scaled = scaler_wine.fit_transform(X_train_wine)
X_test_wine_scaled = scaler_wine.transform(X_test_wine)
# 모델 학습
model_wine = LogisticRegression(max_iter=1000, random_state=42)
model_wine.fit(X_train_wine_scaled, y_train_wine)
# 예측
y_pred_wine = model_wine.predict(X_test_wine_scaled)
print("모델 학습 완료")
모델 학습 완료
In [28]:
# Confusion Matrix 계산 및 시각화
cm_wine = confusion_matrix(y_test_wine, y_pred_wine)
plt.figure(figsize=(10, 8))
sns.heatmap(cm_wine, annot=True, fmt='d', cmap='Blues',
xticklabels=wine_data.target_names,
yticklabels=wine_data.target_names)
plt.ylabel('Actual')
plt.xlabel('Predicted')
plt.title('Multi-class Confusion Matrix')
plt.show()
print("Confusion Matrix:")
print(cm_wine)

Confusion Matrix: [[12 0 0] [ 0 14 0] [ 0 1 9]]
In [29]:
# 각 클래스별 Precision, Recall, F1 Score 계산
from sklearn.metrics import precision_recall_fscore_support
precision_per_class, recall_per_class, f1_per_class, support = precision_recall_fscore_support(
y_test_wine, y_pred_wine, average=None
)
print("=== 클래스별 평가 지표 ===")
for i, class_name in enumerate(wine_data.target_names):
print(f"\n{class_name}:")
print(f" Precision: {precision_per_class[i]:.4f}")
print(f" Recall: {recall_per_class[i]:.4f}")
print(f" F1 Score: {f1_per_class[i]:.4f}")
print(f" Support: {support[i]}")
=== 클래스별 평가 지표 === class_0: Precision: 1.0000 Recall: 1.0000 F1 Score: 1.0000 Support: 12 class_1: Precision: 0.9333 Recall: 1.0000 F1 Score: 0.9655 Support: 14 class_2: Precision: 1.0000 Recall: 0.9000 F1 Score: 0.9474 Support: 10
In [30]:
# Macro, Micro, Weighted 평균 계산
precision_macro = precision_score(y_test_wine, y_pred_wine, average='macro')
precision_micro = precision_score(y_test_wine, y_pred_wine, average='micro')
precision_weighted = precision_score(y_test_wine, y_pred_wine, average='weighted')
recall_macro = recall_score(y_test_wine, y_pred_wine, average='macro')
recall_micro = recall_score(y_test_wine, y_pred_wine, average='micro')
recall_weighted = recall_score(y_test_wine, y_pred_wine, average='weighted')
f1_macro = f1_score(y_test_wine, y_pred_wine, average='macro')
f1_micro = f1_score(y_test_wine, y_pred_wine, average='micro')
f1_weighted = f1_score(y_test_wine, y_pred_wine, average='weighted')
print("=== Average Metrics Comparison ===")
print(f"\n{'Metric':<15} {'Macro':<10} {'Micro':<10} {'Weighted':<10}")
print("-" * 45)
print(f"{'Precision':<15} {precision_macro:<10.4f} {precision_micro:<10.4f} {precision_weighted:<10.4f}")
print(f"{'Recall':<15} {recall_macro:<10.4f} {recall_micro:<10.4f} {recall_weighted:<10.4f}")
print(f"{'F1 Score':<15} {f1_macro:<10.4f} {f1_micro:<10.4f} {f1_weighted:<10.4f}")
=== Average Metrics Comparison === Metric Macro Micro Weighted --------------------------------------------- Precision 0.9778 0.9722 0.9741 Recall 0.9667 0.9722 0.9722 F1 Score 0.9710 0.9722 0.9720
In [31]:
# Classification Report
print("=== Classification Report ===")
print(classification_report(y_test_wine, y_pred_wine,
target_names=wine_data.target_names))
=== Classification Report ===
precision recall f1-score support
class_0 1.00 1.00 1.00 12
class_1 0.93 1.00 0.97 14
class_2 1.00 0.90 0.95 10
accuracy 0.97 36
macro avg 0.98 0.97 0.97 36
weighted avg 0.97 0.97 0.97 36