
개요
dslr은 ecole42의 머신러닝 프로젝트로, 학생 데이터셋을 사용하여 해리포터 기숙사를 할당하는 AI를 만드는 프로젝트다. 먼저 주어진 데이터를 적절한 방식으로 전처리한다. 다음으로 히스토그램과 산점도를 통해 데이터를 시각화하고 AI를 학습시킬 특성을 선택한다. 마지막으로 로지스틱 회귀를 통해 AI를 개발한다.
요구사항
- Python 버전 3.12.3
설치
# python3 -m venv venv
# source venv/bin/activate
pip3 install -r requirements.txt
실행 방법
python 01.describe.py dataset_train.csv
python 02.histogram.py dataset_train.csv --all
python 03.scatter_plot.py dataset_train.csv --all
python 04.pair_plot.py dataset_train.csv --all
python 05.logreg_train.py dataset_train.csv
python 06.logreg_predict.py dataset_test.csv weights.csv
python 07.evaluate.py
데이터 시각화
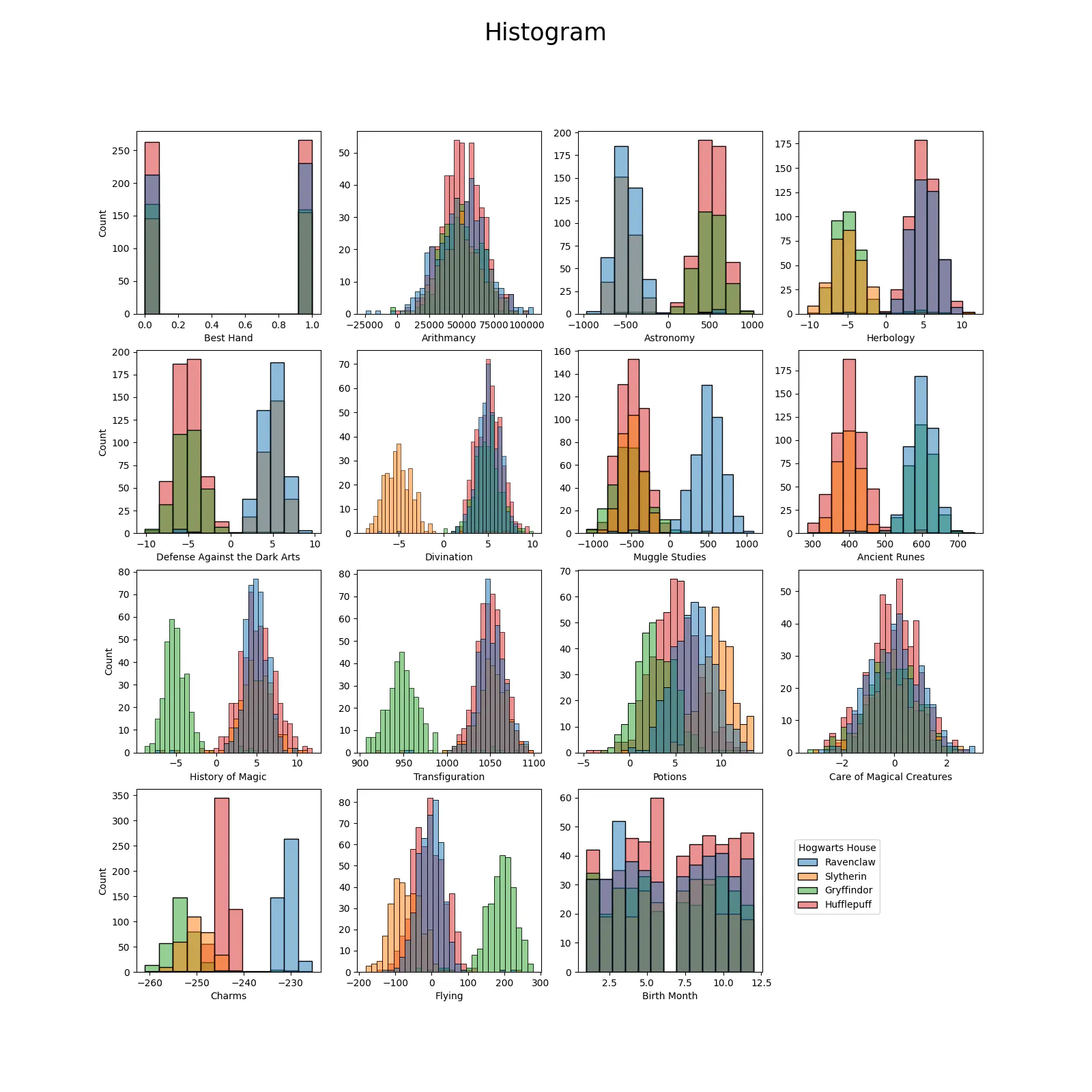
히스토그램
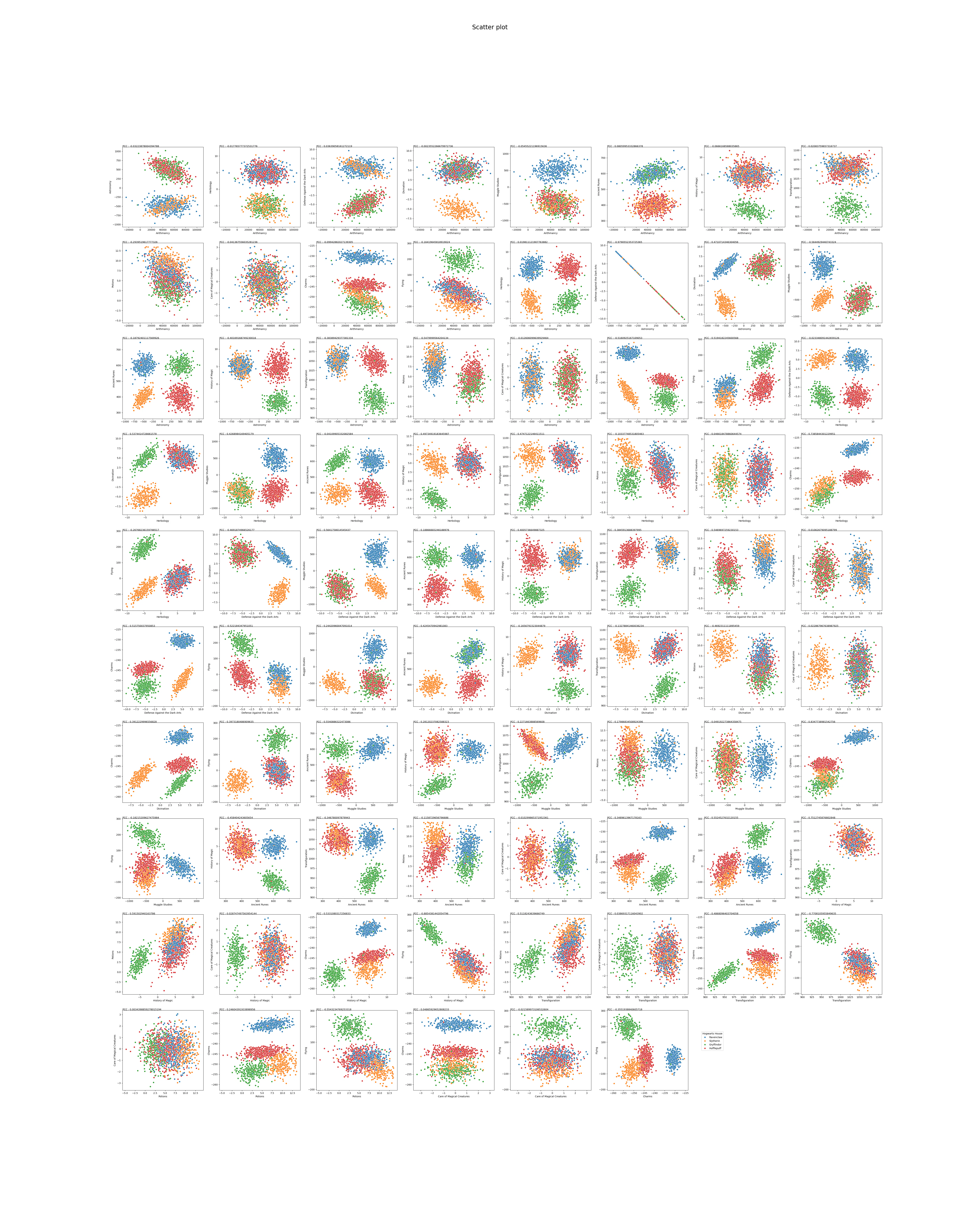
산점도
페어 플롯
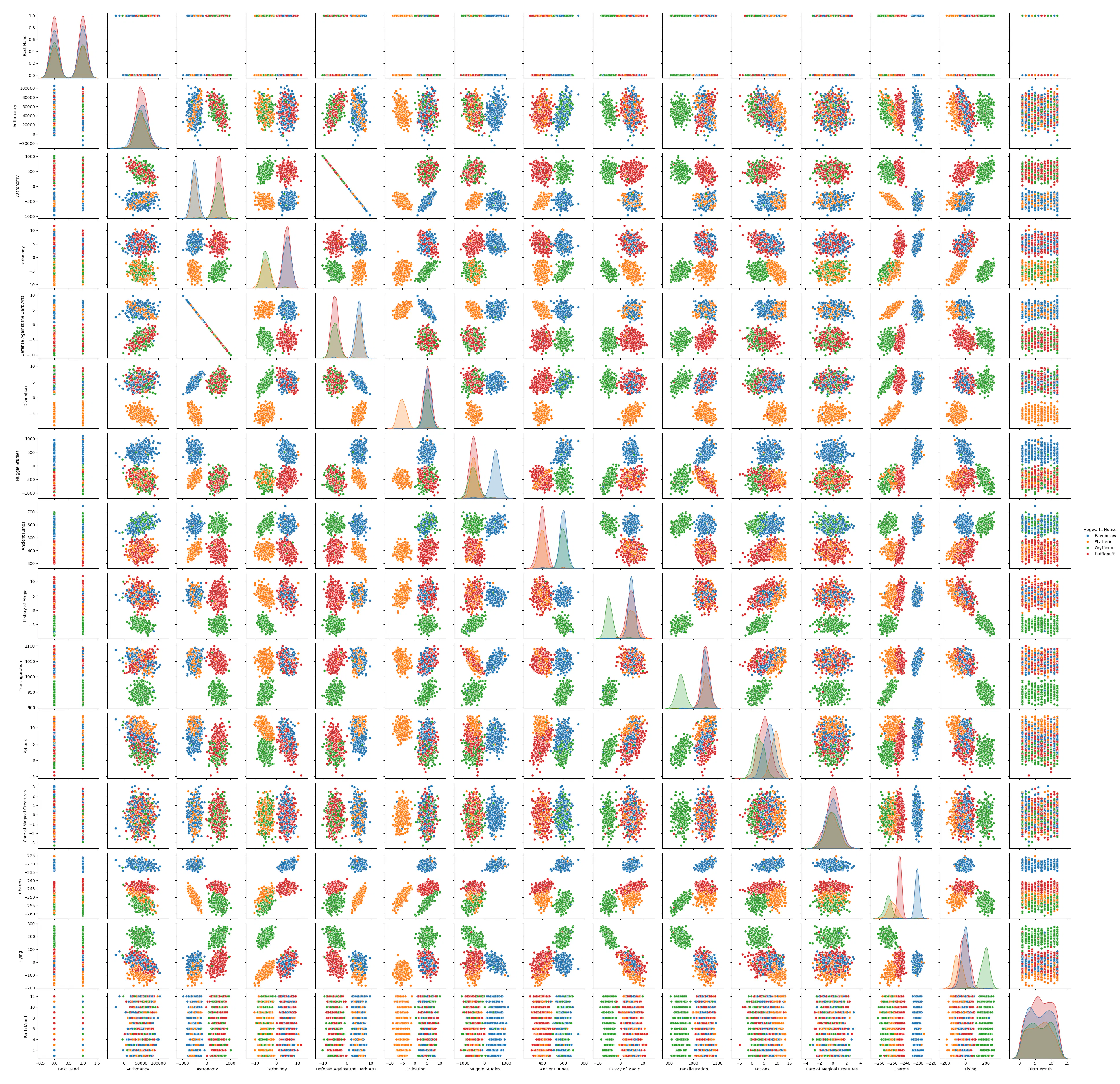
- 동질적 특성: Arithmancy, Potions, Care of Magical Creatures
- 유사한 특성: (Astronomy vs Defense Against the Dark Arts), (Transfiguration vs History of Magic vs Flying)
보너스 기능
- describe.py: pandas.describe와 유사한 추가 필드 제공 (
count,unique,top,freq) - 다중 그래프 및 정보: 히스토그램, 산점도
- 미니 배치(Mini-Batch) 학습
- 확률적(Stochastic) 학습
- 각 알고리즘별 학습 손실 그래프
학습 알고리즘
이 프로젝트는 세 가지 경사 하강법 알고리즘을 지원한다:
- Batch Gradient Descent: 전체 데이터셋을 사용하여 한 번에 업데이트
- Mini-Batch Gradient Descent: 작은 배치 단위로 업데이트 (기본 배치 크기: 5)
- Stochastic Gradient Descent: 각 샘플마다 업데이트
학습 알고리즘을 선택하려면 --algorithm 옵션을 사용한다:
python 05.logreg_train.py dataset_train.csv --algorithm batch
python 05.logreg_train.py dataset_train.csv --algorithm mini-batch
python 05.logreg_train.py dataset_train.csv --algorithm stochastic
각 알고리즘의 학습 손실 그래프는 train-{algorithm}.png 파일로 저장된다.
프로젝트 구조
dslr/
├── 01.describe.py # 데이터셋 통계 정보 출력
├── 02.histogram.py # 히스토그램 시각화
├── 03.scatter_plot.py # 산점도 시각화
├── 04.pair_plot.py # 페어 플롯 시각화
├── 05.logreg_train.py # 로지스틱 회귀 모델 학습
├── 06.logreg_predict.py # 모델을 사용한 예측
├── 07.evaluate.py # 모델 정확도 평가
├── lib/
│ ├── logreg.py # 로지스틱 회귀 핵심 함수
│ ├── math.py # 수학 함수 (평균, 표준편차 등)
│ ├── print.py # 출력 유틸리티
│ ├── validate.py # 데이터 검증 함수
│ └── visualize.py # 시각화 함수
├── dataset_train.csv # 학습 데이터셋
├── dataset_test.csv # 테스트 데이터셋
├── dataset_truth.csv # 정답 데이터셋
└── weights.csv # 학습된 모델 가중치 (학습 후 생성)
주요 기능
1. 데이터 전처리 (01.describe.py)
- CSV 파일을 읽고 데이터셋의 통계 정보를 출력한다
- 각 컬럼의 타입, 개수, 고유값, 최빈값, 빈도, 평균, 최소값, 사분위수, 최대값, 표준편차를 계산한다
2. 히스토그램 (02.histogram.py)
- 각 특성별로 기숙사 간 분포를 히스토그램으로 시각화한다
--all옵션으로 모든 히스토그램을 한 번에 생성할 수 있다
3. 산점도 (03.scatter_plot.py)
- 특성 간 상관관계를 산점도로 시각화하고 피어슨 상관계수를 제공한다
--all옵션으로 모든 산점도를 생성할 수 있다
4. 페어 플롯 (04.pair_plot.py)
- 모든 특성 쌍의 관계를 한 번에 시각화한다
- 특성 선택 및 제거 결정에 도움을 준다
5. 모델 학습 (05.logreg_train.py)
- 선택된 특성을 사용하여 로지스틱 회귀 모델을 학습한다
- 각 기숙사(Gryffindor, Hufflepuff, Ravenclaw, Slytherin)에 대해 이진 분류기를 학습한다
- 학습된 가중치를
weights.csv에 저장한다 - 학습 손실 그래프를 생성한다
6. 예측 (06.logreg_predict.py)
- 학습된 모델을 사용하여 테스트 데이터셋의 기숙사를 예측한다
- 예측 결과를
houses.csv에 저장한다
7. 평가 (07.evaluate.py)
- 예측 결과와 정답을 비교하여 모델의 정확도를 계산한다
특성 선택
분석 결과, 다음 특성들이 제거되었다:
- 동질적 특성 (기숙사 간 차이가 거의 없음): Arithmancy, Potions, Care of Magical Creatures
- 유사한 특성 (높은 상관관계로 인한 중복): Astronomy, Transfiguration, Flying
최종 모델은 다음 특성들을 사용한다:
- Defense Against the Dark Arts
- History of Magic
- 기타 유용한 특성들