
Introduction
- 발표를 해야하는데 ppt 리모컨을 깜박하고 가져오지 않았을 때 있으신가요?
- 과자를 먹으며 유튜브를 보는데 키보드에 손을 대기 싫으신가요?
Gesto는 카메라로 손의 제스처를 인식해서 PPT, Youtube 를 조작할 수 있는 프로그램입니다.
발표영상
Features
-
동작인식 시작: 양 손바닥을 화면에 보여주기
-
동작인식 종료: 양 주먹을 화면에 보여주기
-
PPT 모드
- 다음 슬라이드: Swipe Left (왼손은 주먹, 오른손은 왼쪽으로 스와이프)
- 이전 슬라이드: Swipe Right (오른손은 주먹, 왼손은 오른쪽으로 스와이프)
- 최소화: Pinch In (한손은 주먹, 다른 손은 pinch in)
- 최대화: Pinch Out (한손은 주먹, 다른 손은 pinch out)
-
Youtube 모드
- 앞으로 5초: Swipe Left (왼손은 주먹, 오른손은 왼쪽으로 스와이프)
- 뒤로 5초: Swipe Right (오른손은 주먹, 왼손은 오른쪽으로 스와이프)
- 최소화: Pinch In (한손은 주먹, 다른 손은 pinch in)
- 최대화: Pinch Out (한손은 주먹, 다른 손은 pinch out)
- 시작: Play (한손은 주먹, 다른손은 클릭하듯이)
- 정지: Pause (시작과 동일)

-
Always on Top
- 검지와 중지로 V자 2초간 유지
- 해제시 거꾸로된 V자로 2초간 유지
Implemetation Processes
1. 프로젝트 시작
에드인에듀 Physical AI 과정에서 하게 된 첫번째 그룹 프로젝트. 해당 6개월 과정에는 총 4가지의 굵직한 그룹 프로젝트가 있는데 그 중 첫 번째는 바로 딥러닝을 이용한 서비스를 만드는 것이었다. 조원은 알아서 편하게 구성할 수 있어서 나 포함 4명이 그룹과제를 하게 되었다. 간단한 아이스브레이킹 이후 각자 할 수 있는 일들이 무엇인지 그리고 어떤 주제를 해야할지 의견을 나누었고, 그 결과 우리가 배운 LSTM 모델과 MediaPipe 그리고 PyQT를 이용해서 PPT를 제어하는 프로그램을 만드는 아이디어가 나왔다.
듣자마자 "아 이거다!" 라는 느낌이 왔다. 학원에서 하는 모든 프로젝트들(일일, 개인, 그룹)은 항상 마지막에 결과물을 발표하는 시간을 갖는다. 만약 프로젝트 발표일에 우리가 만든 프로그램으로 발표를 진행한다면 좋겠다. 발표와 시연을 동시에 할 수 있으니까.
2. 자료조사 & 기술조사
posture vs gesture
움직임에는 posture 와 gesture 두 가지가 있다.
Posture vs Gesture
- posture: 정지된 동작. 시간과 상관없이 동작이 항상 같음
- gesture: 움직이는 동작. 시간에 따라 동작이 달라짐.
posture 는 정지동작으로 MediaPipe 를 이용하여 관절 위치 계산만으로 동작을 인식할 수 있다. 반면 gesture 는 이전 동작 데이터 값과 현재 데이터 값이 모두 고려가 되어야 하는 시계열 데이터(sequential data) 이므로 RNN (순환 신경망) 을 사용해야한다.
MediaPipe
MediaPipe는 구글이 개발한 오픈소스 머신러닝 프레임워크로, 웹, 앱, 데스크톱 등 다양한 플랫폼에서 영상, 오디오, 센서 데이터를 실시간으로 처리할 수 있는 고성능 AI 솔루션이다.

MediaPipe 는 손의 관절을 21개로 구분하여, 각 관절마다의 x, y, z 좌표값을 반환한다. 이걸 이용하면 손이 어떤 동작을 하는지 알 수 있다. 예를 들어, 네 개의 손가락의 TIP 위치가 MCP 보다 낮은위치에 있고, 엄지 TIP이 손바닥쪽을 향해 있다면 주먹을 쥐었다고 생각할 수 있다. 따라서 posture 와 같은 정지 동작은 MediaPipe 만으로도 구현이 가능하다.
LSTM
LSTM(Long Short-Term Memory) 은 순환 신경망(RNN)의 한 종류로, 셀(cell) 상태와 게이트(gate) 메커니즘을 도입해 시간이 지날수록 이전 정보가 희석되거나 소실되는 vanishing gradient 문제를 해결한 것이 특징이다. 제스처와 같은 시간에 따라 변하는 시계열 데이터에서는 “지금 이 순간”뿐 아니라 “그 직전까지의 움직임”이 중요하므로, LSTM을 이용하면 이전 시점들의 맥락을 기억하면서 현재 프레임을 해석할 수 있다.
RNN(Recurrent Neural Network, 순환 신경망) 이란?
시퀀스(시간 순서가 있는 데이터)를 다루기 위한 신경망이다. 같은 가중치를 반복 사용하면서 이전 시점의 은닉 상태를 현재 입력과 함께 넣어, “과거 맥락”을 어느 정도 기억한다. 그래서 음성·텍스트·동작처럼 순서가 중요한 데이터에 쓰인다.
수업때에는 LSTM 에 대해 배워서 프로젝트에도 LSTM을 사용하였지만, 지금 이 회고를 작성하면서 조사를 해보니 LSTM 보다 가벼운 GRU 라는 것도 있다는 것을 알게되었다. 이미 프로젝트는 끝났지만 한번 LSTM 과 GRU의 성능을 비교해보는 것도 좋을 것 같다.
Pynput
인식된 제스처를 바탕으로 키보드 입력을 트리거 할 수 있는 라이브러리로 pynput 을 사용하였다.
3. 설계
발표를 하다보면 무의식적으로 손을 사용할 때가 많은데, 그때마다 의도치 않은 동작이 트리거 되지 않기 위해 안전장치가 필요했다. 그래서 우리는 2가지 방법을 쓰기로 했다.
(1) 동작감지 시작/종료 트리거 도입
두 손바닥을 2초간 보여주면 MediaPipe 관절의 색이 변하면서 동작 감지가 시작 되었음을 알린다. 반대로 두 주먹을 2초간 보여주면 관절의 색이 회색으로 변하면서 동작 감지가 종료되었음을 알린다. 동작 감지의 시작과 종료를 트리거 하는 동작은 의도적으로 posture 로 설정하였다. 사용자 입장에서 트리거 동작과 조작 동작이 구분되어서 이해하기 쉽기 때문이다.

(2) 동작은 일상에서 자주 사용하지 않는 동작으로 한다.
두 손을 사용해서 동작을 해야만 하는 것으로 동작을 구성하였다. MediaPipe로 양손이 인식이 되어야 하고, 한 손이 반드시 주먹을 쥐어야지만 Gesture 동작을 판별하도록 했다.
| 동작감지 X | 동작감지 O |
|---|---|
 |  |
4. 데이터셋과 훈련
우리는 촬영자마다 다른 거리와 프레임 문제를 해결하기 위한 자체 수집 framework 를 제작하였다. 제스처를 녹화할 때 다 똑같은 30fps 1초로 녹화를 하기 위해서였다. 또한 녹화본을 저장할 때는 .npy 파일로 저장했다. 이렇게 하면 데이터셋의 용량을 획기적으로 줄일 수 있기 때문이다. 다만 해당 파일은 바이너리 파일이기 때문에 녹화가 잘 되었는지 확인할 길이 없었다. 그래서 디버깅을 위한 visualise 스크립트를 따로 만들었다.
| data framework | visualize npy |
|---|---|
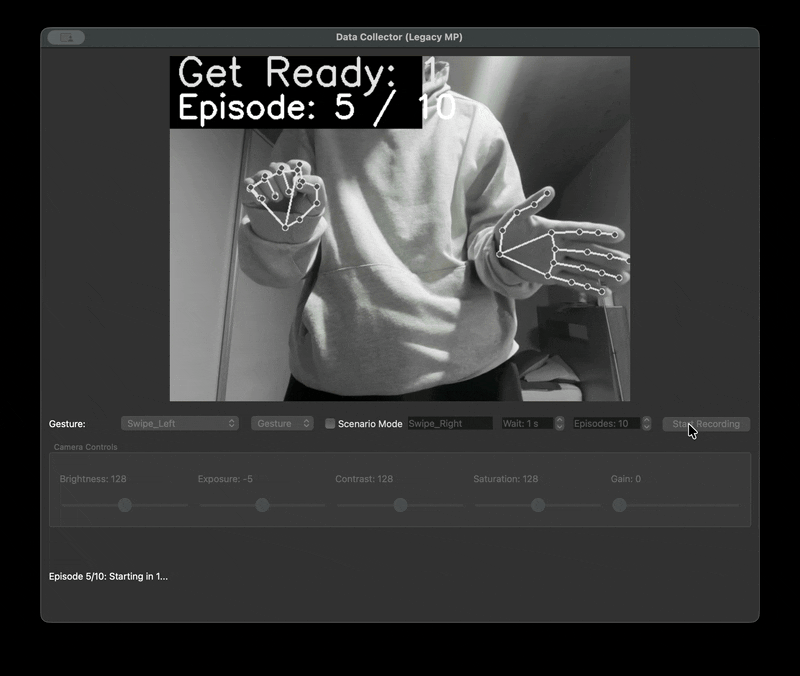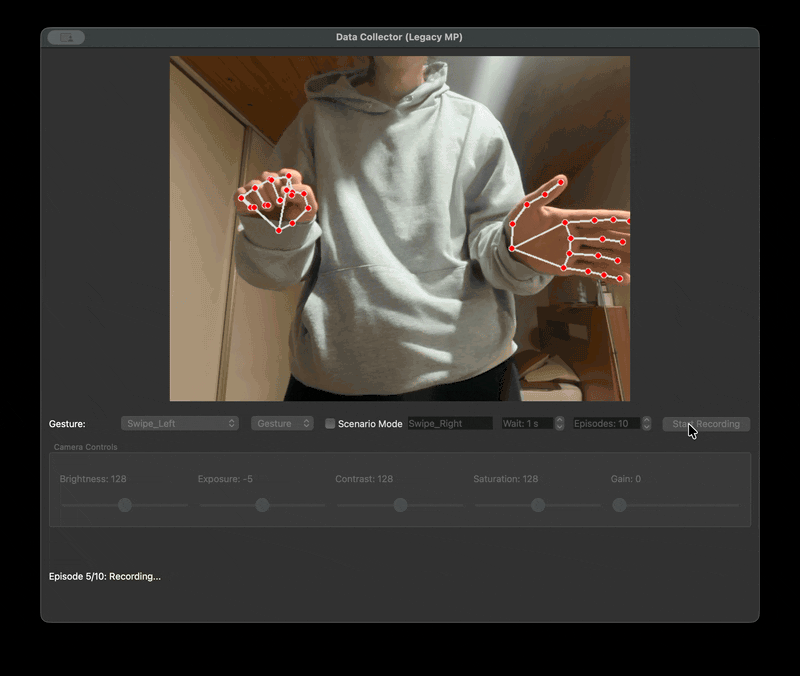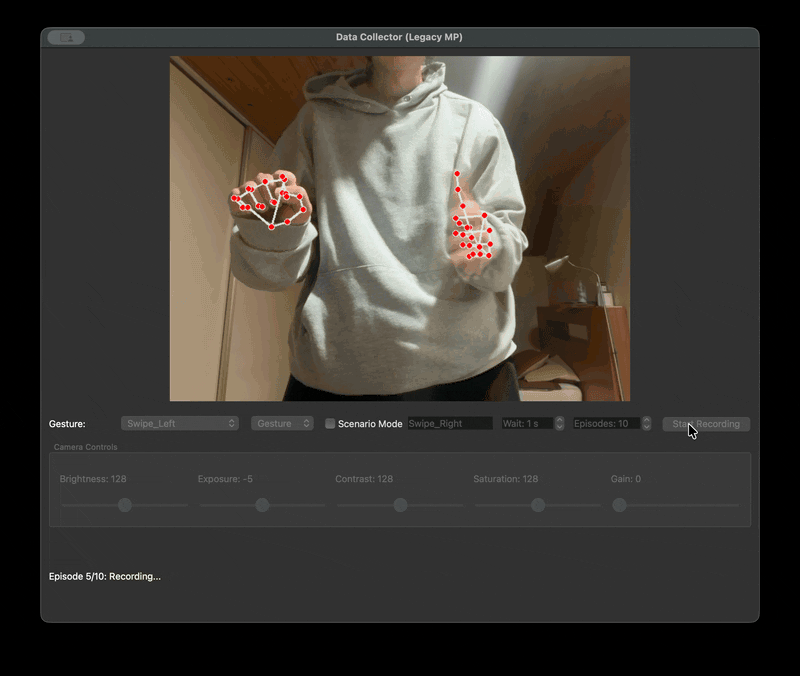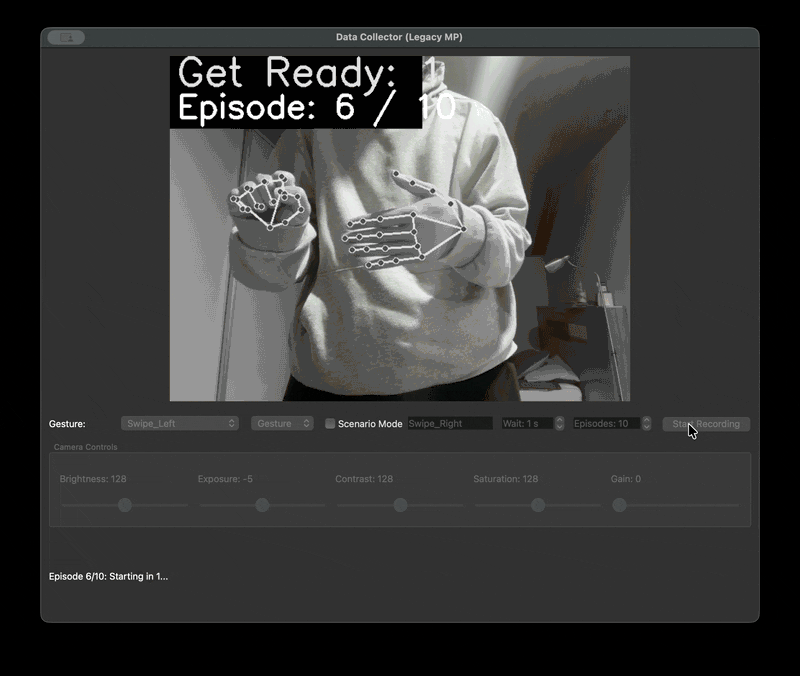 | 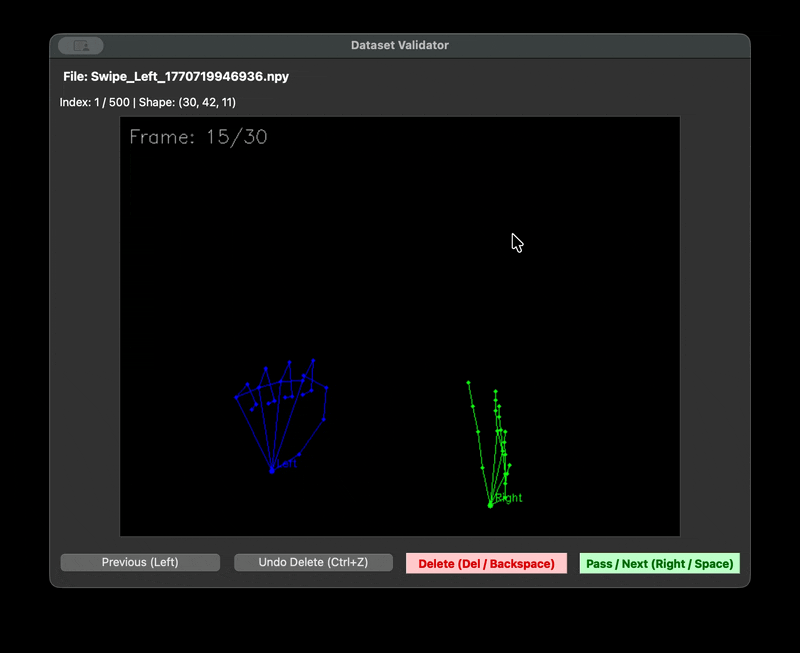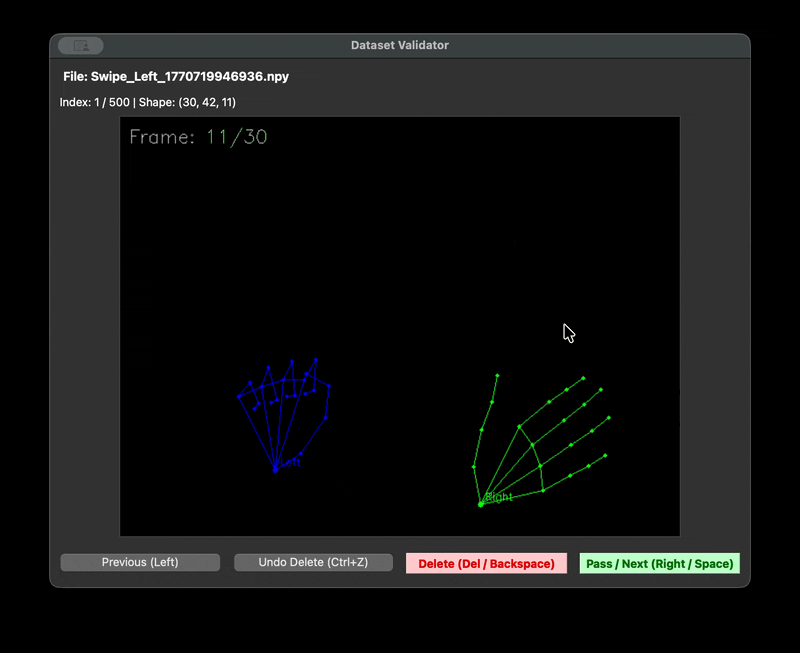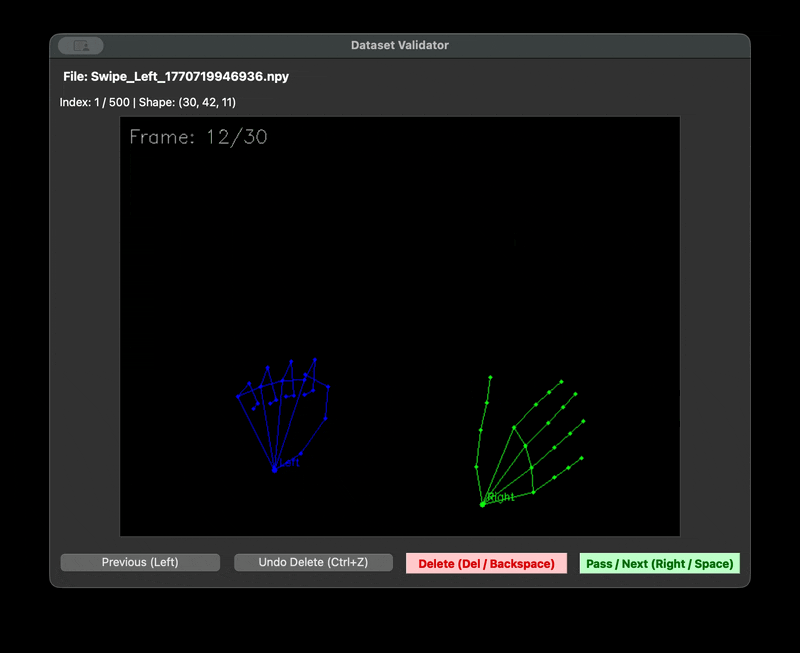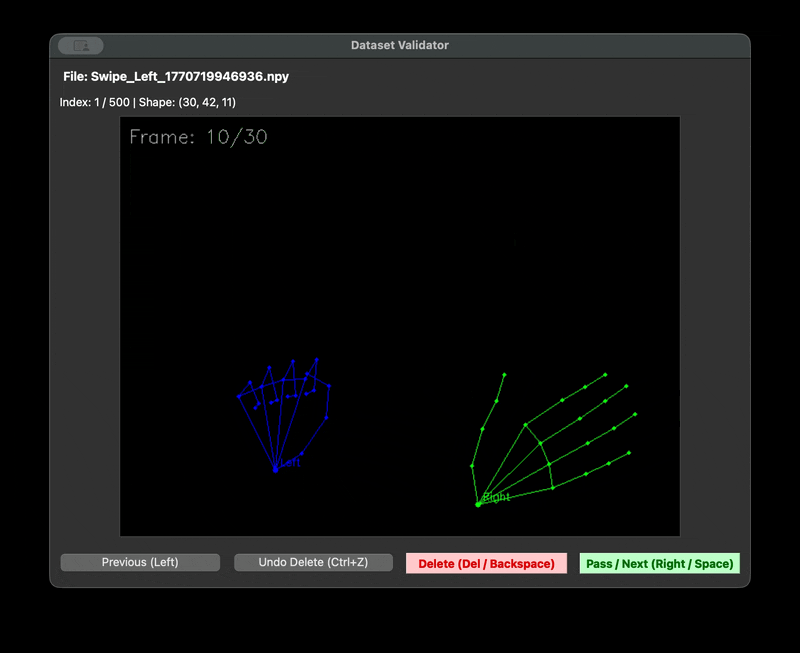 |
모델을 훈련시키기 위한 라이브러리는 Tensorflow 를 이용해서 신경망을 구성하였다.
SEQUENCE_LENGTH = 30 # 1초 * 30fps
LANDMARKS_COUNT = 42 # 양손이라서 21 * 2
COORDS_COUNT = 3 # x, y, z
INPUT_SHAPE = (SEQUENCE_LENGTH, LANDMARKS_COUNT * COORDS_COUNT)
model = Sequential([
# 첫 레이어는 유닛을 넉넉히 주어 특징을 충분히 뽑습니다.
LSTM(128, return_sequences=True, input_shape=INPUT_SHAPE),
Dropout(0.2),
# 두 번째 층은 64개로 줄여 정보를 압축합니다.
LSTM(64, return_sequences=False),
Dropout(0.2),
# Dense 층은 너무 크지 않게 하여 연산 속도를 확보합니다.
Dense(32, activation='relu'),
# L2 규제는 학습 시 과적합을 막아주지만, 추론 속도에는 영향을 주지 않으므로 유지합니다.
Dense(num_classes, activation='softmax')
])
훈련을 마친 모델을 테스트 했는데 원하는 성능이 나오지 않았다. 조사해보니 아래와 같은 이슈가 있었다.
-
제스처가 처음과 끝동작으로만 인식이 되는 문제
예를들어 스와이프의 동작은, 왼쪽에서 오른쪽으로 움직일 때 중간 동작이 있어야 인식이 되어야 한다. 하지만 우리 모델은 처음이나 끝 동작으로도 제스처가 인식이 되었다. 녹화 영상을 살펴보니 제스처의 처음과 끝에 프레임이 많이 집중되어서 생긴 문제였다.
해당 문제를 해결하기 위해 녹화를 할때 최대한 30프레임이 모든 움직임을 담을 수 있도록 했다. 또한 모든 동작의 처음과 끝을 녹화해서 No Gesture 라는 클래스를 만들었다. 이렇게 하면 처음과 끝 동작만으로는 제스처가 감지되지 않는다.
-
MediaPipe 인식이 안되는 프레임이 존재
손이 움직일때 MediaPipe 인식 문제로 한 순간 손이 사라졌다가 다시 나타나는 현상이 있었다. 그래서 비정상적인 프레임은 앞과 뒤 프레임의 위치를 이용해서 선형보간을 했다.
5. Feature Engineering
제스처의 인식률은 위의 방법으로 많이 개선이 되었지만 아직도 우리가 원하는 만큼의 퍼포먼스는 아니었다. 예를들어 Pinch 를 했는데 Swipe 로 인식이 된다던지, Play Pause 동작을 했는데 Swipe 가 된다던지 하는 문제가 있었다. 여러가지 자료를 찾아본 결과, 제스처의 인식률을 개선하기 위해 모델에 feature 를 더 추가해서 주입한다는 자료를 보게되었다.
우리가 하는 제스처는 Swipe, Pinch, Play & Pause 의 동작들이고 다른 한 손은 반드시 주먹을 쥐어야 하는 특징이 있다. 그래서 우리는 동작의 기하학적 위치 3채널(x, y, z)에다가 제스처를 구분할 수 있는 특징들을 더해 11채널로 만들어 훈련을 시켰다.
# 왼손 정보
new_data[i, :, 3] = left_feats[0] # Is_Fist: 주먹인지 아닌지
new_data[i, :, 4] = left_feats[1] # Pinch_Dist: 엄지와 검지 사이의 거리
new_data[i, :, 5] = left_feats[2] # Thumb_V: 엄지의 움직임 속도
new_data[i, :, 6] = left_feats[3] # Index_Z_V: 검지의 Z 방향 움직임 속도
# 오른손 정보
new_data[i, :, 7] = right_feats[0] # Is_Fist: 주먹인지 아닌지
new_data[i, :, 8] = right_feats[1] # Pinch_Dist: 엄지와 검지 사이의 거리
new_data[i, :, 9] = right_feats[2] # Thumb_V: 엄지의 움직임 속도
new_data[i, :, 10] = right_feats[3] # Index_Z_V: 검지의 Z 방향 움직임 속도
이렇게 만들어서 훈련을 했더니 인식이 잘되고 동작간의 간섭이 없이 인식률 99% 가 잘 나왔다. 만약 인식이 잘 안되면 임계점을 조절해서 감도 조절을 하려고 했으나 그럴 필요는 없었다.